| LTE Quick Reference Go Back To Index Home : www.sharetechnote.com | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
PUCCH (Physical Uplink Control Channel) carries a set of information called "UCI(Uplink Control Information)". (This is similar to PDCCH which carries DCI (Downlink control information)". Depending on what kind of information the UCI in PUCCH carries, PUCCH is classified into various formation as follows.
You may see a lot of different way of describing these formats depending on situation. It may be confusing at the beginning, but it would be better for you to get familiar with those different way of expression. You may want a single big table which has every details, but you will notice that those big table would be even more confusing.
So I will try to describe these formats in this page in various ways with a little bit different focus. You will see all of these are saying the same thing.. but in a little bit different perspective.
In 3GPP 36.213, section 10.1 UE procedure for determining physical uplink control channel assignment. The PUCCH format is summarized as follows.
Following is a tabular format of description of specification described above in 3GPP specification (36.213-10.1.1 PUCCH format information).
Following is another tabular format of description of specification, this is intended to give you idea on the contents of HARQ and CSI.
NOTE : 'Number of Bits' here the bit length after PUCCH channel coding. In short, the number of ACK/NACK bits does not change by channel coding process, but the number of CSI (e.g, CQI) increases to 20 bits. See PUCCH Channel Coding page.
Important Questions about PUCCH
Physical Layer Configuraion for PUCCH
If you are mostly working on higher layer signaling (e.g, RRC or NAS) and has to configure PUCCH details in RRC message, you would have some difficulties of understanding/setting physical layer configuration of PUCCH. Following topics would help you in this aspect.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Source https://blog.csdn.net/m_052148/article/details/51982050
LTE上行物理层传输机制(1)-PUSCH上行跳频之Type1频率跳频
版权声明:本文为博主辛苦原创,转载时请注明原文链接(http://blog.csdn.net/m_052148),谢谢 https://blog.csdn.net/m_052148/article/details/51982050
1.什么是PUSCH频率跳频(PUSCH Frequency Hopping)
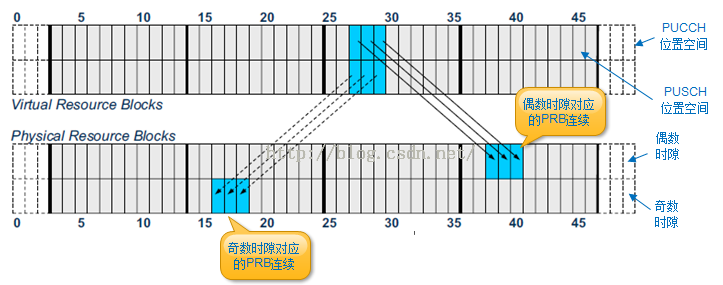
博文《LTE下行物理层传输机制(9)-集中式和分布式资源映射》中提到了分布式的下行资源分配,这种资源分配方式可以有效利用频率的分集效应,增加信号的抗干扰作用。实际上在上行传输过程中,也存在着类似的分布式资源分配,即连续的VRB对映射到不连续的PRB对中,这种方式就叫做PUSCH频率跳频(PUSCH Frequency Hopping)。由于上行分配的RB必须使用连续的子载波,因此eNB分配的VRB必须是连续的,并且同一个时隙内连续的VRB必须映射到连续的PRB,如下图所示。
2.为什么要采用PUSCH跳频
采用跳频是为了利用频率的分集效应,增加信号的抗干扰作用。不妨首先考虑下面图1这种RB分配方式。在图1中,eNB在每个子帧subframe的每个时隙slot都分配了若干个连续的RB,用于PUSCH的传输,这个时候看起来并没有问题。
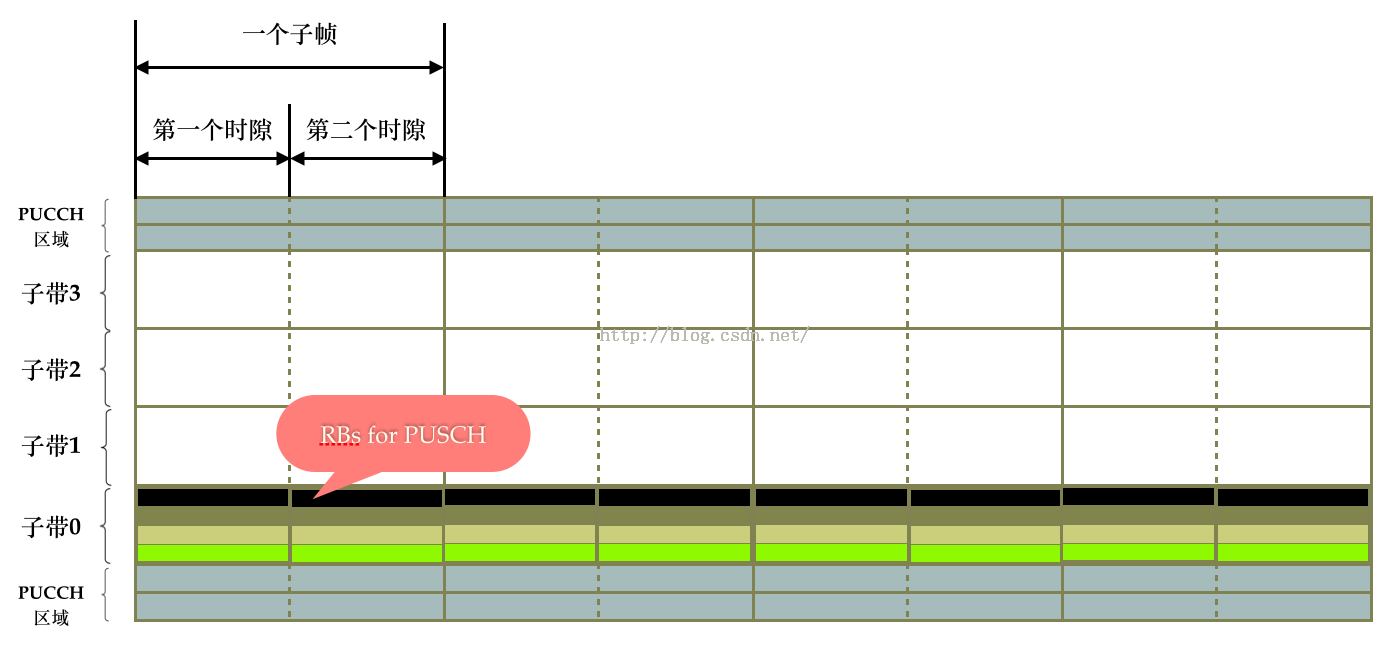
(图1)
然而在某个时刻,系统突然出现了较强的干扰,并且该干扰正好出现在已分配的RB附近,如图2所示。如果这个时候系统没有其他的抗干扰措施,势必会影响PUSCH数据的传输。
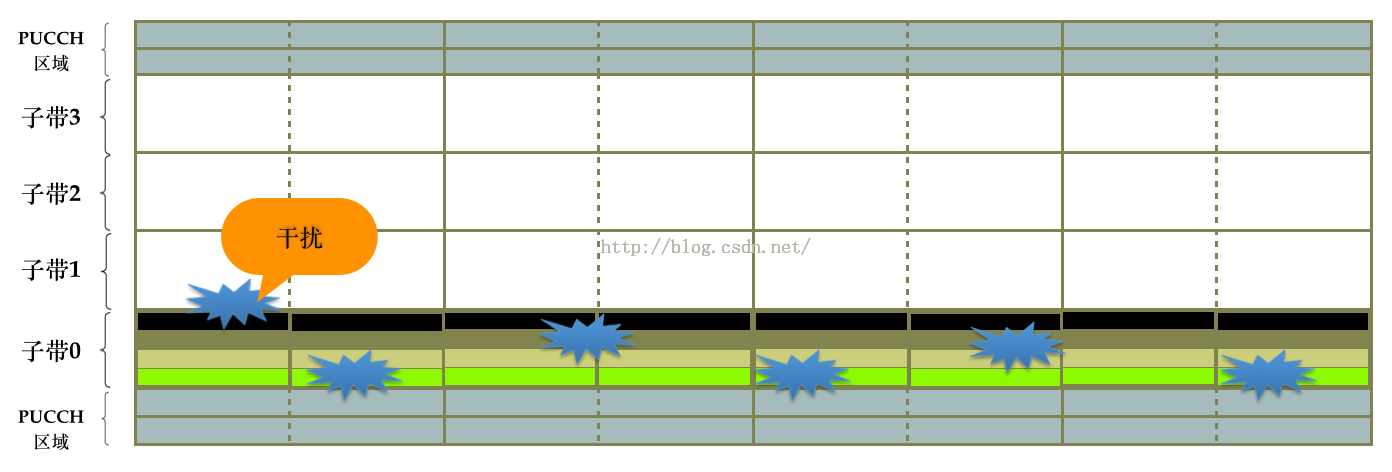
(图2)
在这种情况下,为了提高数据传输的可靠性,选择PUSCH跳频可以是其中的一种方案(当然我们在实际设计算法的时候,也会综合采用其他的一些调度策略,因为不涉及到协议规范内容,这里就不做说明)。我们可以采用图3所示的这种跳频方式,这种跳频模式叫做子帧间跳频(inter-subframe hopping)。子帧间跳频的策略思想是在不同的子帧里分配的RB位置要错开,从而达到分布式的目的。
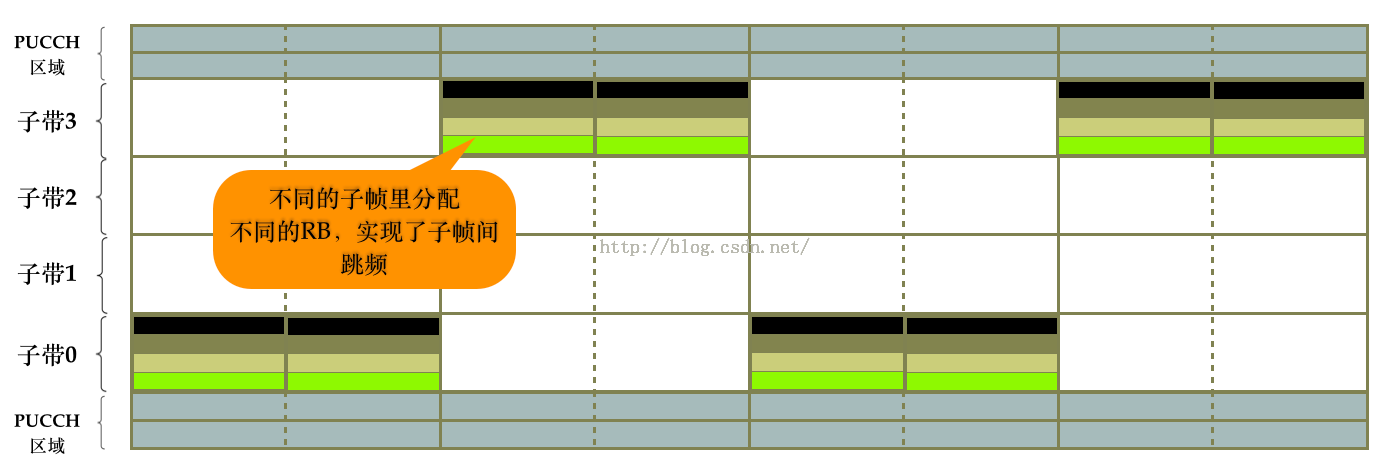
(图3 子帧间跳频)
图3所示的子帧间的跳频模式虽然达到了频率分集的效果,但是同一个子帧内的RB并没有分开,因此这种跳频方式并不彻底,还可以继续优化,所以出现了图4所示的这种跳频方式。图4的这种跳频模式叫做子帧内和子帧间跳频(IntraAndInter-subframe hopping)。
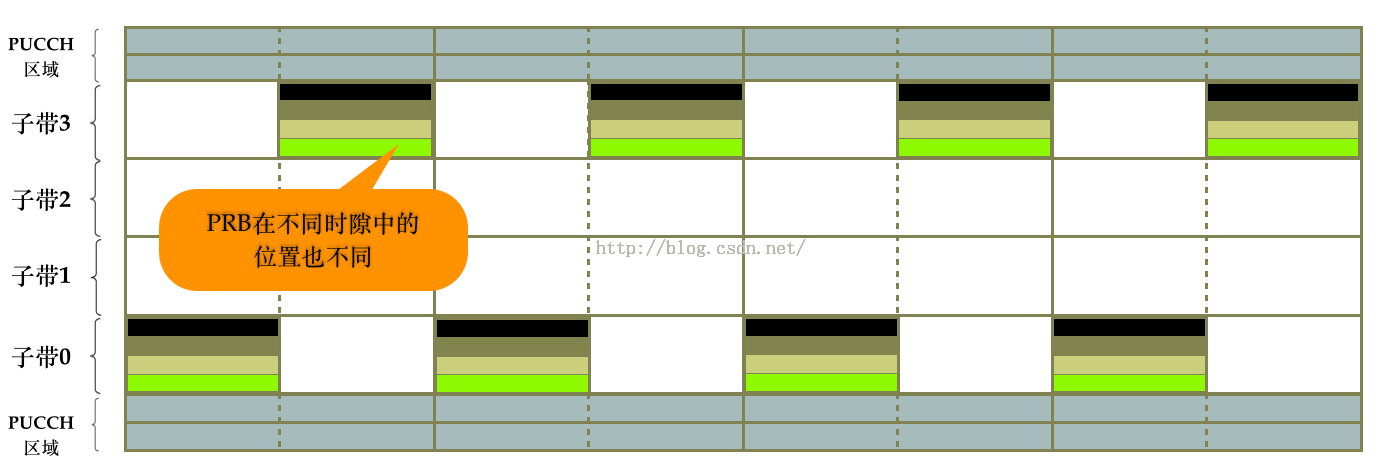
(图4 子帧内和子帧间跳频)
图4所示的跳频方式能明显看到存在着一定的规律性:不同子帧间的偶数时隙与偶数时隙、奇数时隙与奇数时隙,它们的PRB位置是相同的。因为实际环境中的干扰存在着诸多的不确定性,因此如果PRB的映射位置不那么规律一点,则频率分集效果会更好些,因此实际分配时会出现诸如图5所示的子帧内和子帧间跳频。
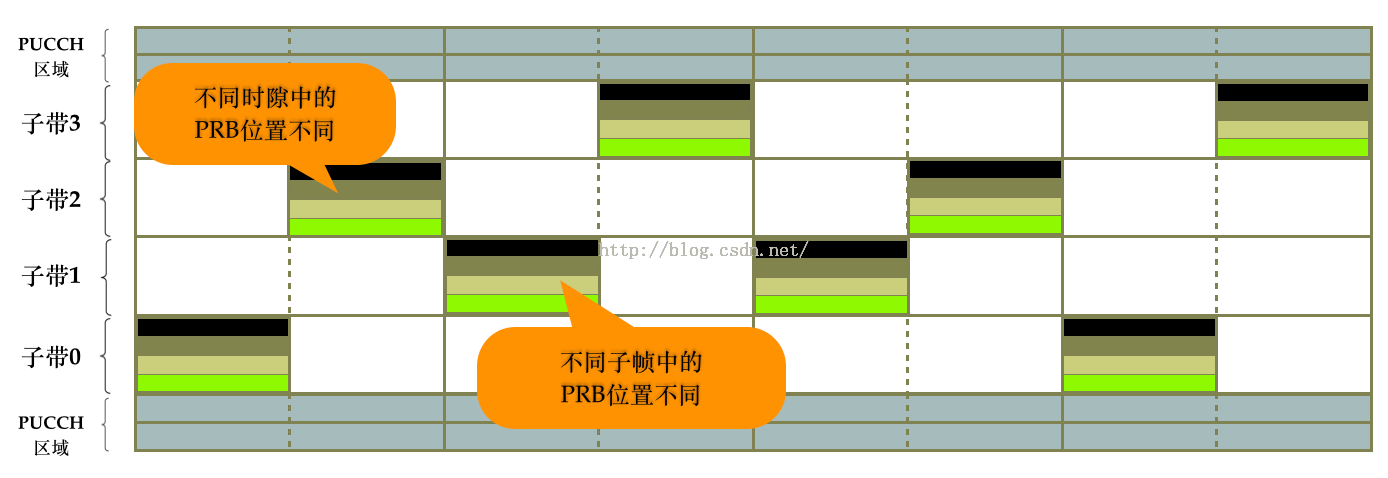
(图5)
上面的这几种跳频方式都可能存在于实际的网络中,如果你只是想了解一下PUSCH跳频的大概内容,那么看到这里就可以了,但如果你是专业的开发人员,马上要进行这方面的代码编写,或者你想更深入的了解这方面的内容,那么就需要继续阅读接下来的内容。因为上面这些跳频图是由下面这些数学公式推导出来的。
3.UE如何判断是否需要进行跳频
在使用数学公式推导PUSCH的PRB跳频位置之前,先介绍下UE是如何判断某个上行子帧是采用跳频还是不跳频的。这里有个总的原则,就是:如果DCI0中的PUSCH跳频比特位(frequency hopping field)被设置为1,那么UE将执行PUSCH频率跳频,否则将不执行跳频。如下图黄色区域标注所示。

如果UE收到了来自eNB的DCI0码流,那么执行跳频的UE,可以通过解析相同传输块最近一次的DCI0码流,来决定子帧n第一个时隙PRB的起始位置。换句话说,如果本次TTI收到了DCI0则按照本次的DCI0解析(对应新传),本次没有收到DCI0但上一次的有,则按照上次的DCI0解析(对应重传)。因为上行RB(无论是VRB还是PRB)是连续的,一旦有了第一个时隙的PRB起始位置,加上DCI中可以解析出的RB个数,就可以知道第一个时隙的所有PRB位置,再根据特定的映射规则(后文将描述这种规则),就可以知道第二个时隙的所有PRB位置。
具体来说,UE不是每次发送上行数据都需要DCI0来分配RB资源,比如进行非自适应重传或者上行SPS,或者发送MSG3,这几种场景都不需要eNB通过DCI0分配RB。因此除了上行新传、自适应重传这类PDCCH会携带DCI0的场景之外,还有下面这三种不带DCI0的场景需要考虑:
(1)UE执行非自适应重传
这种情况下,虽然eNB并不下发DCI0,但之前新传的时候是有DCI0的,UE只需要查看之前的DCI0中,该TB块对应的VRB是否采用了PUSCH跳频,就知道本次非自适应重传是否需要跳频了:如果上次新传是跳频的,那么本次也需要执行同样的PUSCH跳频规则。
(2)UE发送MSG3
MSG3的资源是由MSG2(或者说RAR)的UL_GRANT下发到UE的,如下图所示。MSG3是否采用跳频,依赖于“Hopping flag”字段:如果该值等于1,则表示MSG3需要执行PUSCH跳频。后面的“Fixed size resource block assignment”字段则包含了具体的RB资源信息,与DCI0的类似。

关于RAR的详细内容,请参考博文《LTE-TDD随机接入过程(3)-RAR(MSG2)以及MSG1的重传》。
(3)UE执行上行SPS
如果相同传输块的PUSCH数据,一开始就是被半持续调度的(关于SPS半持续调度的内容以后再专门写),那么是否跳频就由最近一次半持续调度分配时的DCI0跳频信息决定。
PUSCH有2种类型的跳频方式:Type 1 跳频和Type 2 跳频。这两种方式的不同在于,使用Type1方式则意味着同一个子帧内两个时隙的RB位置是由DCI0码流推导出的,而使用Type2方式则意味着两个时隙的RB位置是按照预定义的模型(predefined pattern)进行的,此时整个上行带宽会被分成若干个子带,PUSCH会在几个子带间进行特定规则的跳频,参考上文中的图3~图5。下文将展开讨论PUSCH跳频的规则,提到的DCI0场景,也适用于MSG3的场景。
4.PUSCH跳频方式1(Type 1 PUSCH Hopping)
eNB发给UE的DCI0码流中包含了PUSCH跳频的信息,见下面截图中的黄色内容所示:

可以看到,对于PUSCH跳频来说,DCI0中携带了2个信息:高位N_UL_hop个比特的跳频信息和低位[ ceil(log2[N_UL_RB * (N_UL_RB + 1) / 2 ])- N_UL_hop ]个比特与第一个时隙RB分配有关的信息。那怎么利用这2个信息来推导两个时隙PRB的位置呢?下面一步步的来拆解分析这个问题,这个过程可能比较抽象,没关系,最后会举个实际的例子说明。
(1)跳频信息占N_UL_hop个比特,这个参数值是由带宽大小决定的,具体见下表。比如10M带宽占用50个RB,则N_UL_hop=2。

(2)如果当前是Type1方式的跳频,则如下图所示,第一个时隙的PRB起始位置用变量n_S1_PRB(i)表示,第二个时隙的PRB起始位置用n_PRB(i)表示。
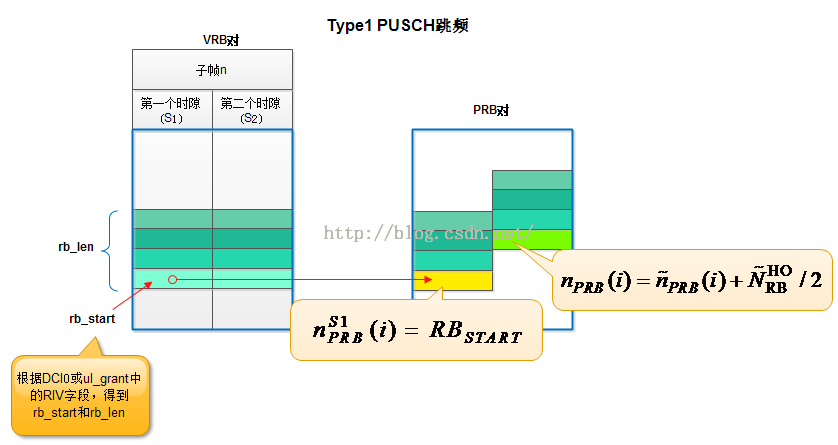
第一个时隙PRB的起始位置等于rb_start,这个值可以从DCI0或UL_GRANT中的RIV字段中直接解码得到,因此接下来的任务主要是解码第二个时隙PRB的起始位置n_PRB(i)。下图是计算第二个时隙PRB起始位置变量n_PRB(i)的过程示意图。从Table8.4-2中可以看到,Nul-hop跳频信息和带宽大小N_UL_RB决定了~n_PRB(i)使用哪个公式以及当前的PUSCH跳频方式(Type1还是Type2)。正如图中的2比特跳频信息NUL_hop=00,此时将选择表格中的公式:
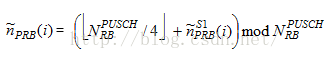
这说明eNB选择的是Type1的PUSCH跳频方式。

(3)如上图所示,在计算~n_PRB(i)的过程中,最终需要用到两个参数N_HO_RB、Nsb,这两个参数是由RRC在SIB2中配置的,分别对应信元pusch_HoppingOffset和信元n-SB,见下文的图A所示。
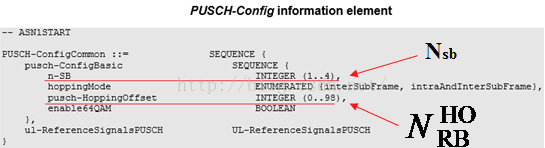
(图A)
至此,就可以知道采用Type1方式跳频后PRB的位置了。以10M带宽为例,如果RRC配置的n-SB=1,pusch-HoppingOffset=4,DCI0中的Nul_hop=00,RIV=270。则:
(A)根据RIV=270可以得到VRB的起始位置rb_start=20,rb_len=6。关于RIV的内容,请参考《LTE-TDD随机接入过程(4)-RIV的解析和Preamble资源的选择》。
(B)pusch-HoppingOffset=4是偶数,所以~N_HO_RB = N_HO_RB = usch-HoppingOffset = 4。
(C)Nul_hop=00,所以采用的是Type1的PUSCH跳频,N_PUSCH_RB = N_UL_RB - ~N_HO_RB - (N_UL_RB mod 2) = 50 - 4 - 0 = 46。
(D)第一个时隙PRB的最低位起始位置 n_S1_PRB(i) = rb_start = 20,长度rb_len=6。
(E)~n_S1_PRB(i) = n_S1_PRB(i) - ~N_HO_RB / 2 = 20 - 4 / 2 = 18。
(F)~n_PRB(i) = ( floor( N_PUSCH_RB / 4) + ~n_S1_PRB(i) ) mod N_PUSCH_RB = (floor(46 / 4) + 18) mod 46 = 29。
(G)第二个时隙PRB的最低位起始位置 n_PRB(i) = ~n_PRB(i) + ~N_HO_RB / 2 = 29 + 4 / 2 = 31,长度rb_len=6。VRB对与PRB对的映射规则如下图所示。
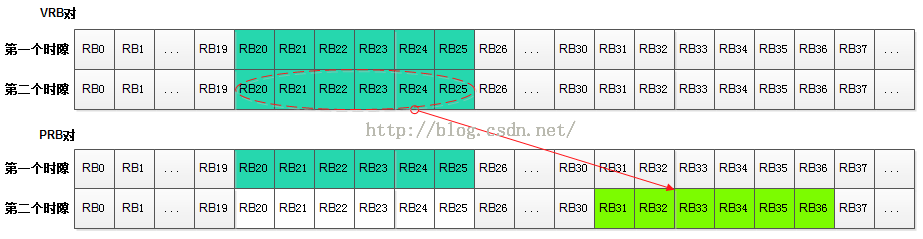
这里对Type1方式的跳频做个总结:在Type1方式中,第一个时隙的PRB位置与不跳频时的PRB位置完全相同,而第二个时隙的PRB位置与第一个时隙相关联。
虽然上面计算得到了两个时隙的PRB位置,但UE不是每次都能这么使用PRB资源,协议规定了一个限制条件:当RRC配置的Hopping-mode是“子帧间跳频”(inter subframe)时,那么第一个时隙的资源分配适用于TB块HARQ传输次数为偶数的场景,第二个时隙的资源分配适用于HARQ传输次数为奇数的场景。这是什么意思呢?如果RRC配置的是“子帧间”跳频,则意味着一个子帧内两个时隙的PRB位置必须是相同的,没有频率的相对偏移,类似于前文中的图3所示。每个HARQ进程中的TB块,都有最大HARQ传输次数限制,比如最大可以传输5次,那么第1次、第3次、第5次传输就是奇数次传输,而第2次、第4次就是偶数次传输。即便此时根据公式计算得到两个时隙的PRB位置不同,但对于偶数HARQ传输次数的子帧,两个时隙的PRB均使用第一个时隙的PRB资源分配,而奇数HARQ传输次数的子帧,两个时隙的PRB均使用第二个时隙的PRB资源分配。
参数Hopping-mode是由RRC的SIB2下发到UE的,与参数N_HO_RB、Nsb在同一个结构体中,见上文的图A,该参数决定了是“子帧间跳频”还是“子帧内和子帧间跳频”。
5.PUSCH跳频方式2(Type 2 PUSCH Hopping)
当采用Type2跳频方式时,PRB与VRB的位置关系将按照预定义的模式进行。因篇幅关系,本节内容将放在下一篇博文中继续介绍。
参考文献:
(1)3GPP TS 36.212 V9.4.0 (2011-09) Multiplexing and channel coding
(2)3GPP TS 36.213 V9.3.0 (2010-09) Physical layer procedures
(3)3GPP TS 36.211 V9.1.0 (2010-03) Physical Channels and Modulation
(4)http://www.sharetechnote.com
(1)3GPP TS 36.212 V9.4.0 (2011-09) Multiplexing and channel coding
(2)3GPP TS 36.213 V9.3.0 (2010-09) Physical layer procedures
(3)3GPP TS 36.211 V9.1.0 (2010-03) Physical Channels and Modulation
(4)http://www.sharetechnote.com